
В статье собраны «фишки» для правильного создания и управления robots.txt, которые применимы только в Яндексе.
Директива clean-param
Если прочитать документацию Яндекса по этой директиве, то число вопросов «а как её использовать-то»? только возрастает.
Поэтому, даю простые и понятные советы-ответы
1. Если вы хотите запретить попадание url с get-параметром «primer» в индекс (не важно, каким по счёту он идёт в url), напишите
clean-param: primerв любой отдельной строке robots.txt
Так как директива clean-param является межсекционной, то для неё не нужен отдельный раздел user-agent: yandex
Гугл будет ругаться на clean-pagam в любом случае — с user-agent, или без. Просто забейте, это ни на что не повлияет.
2. Если у вас есть несколько «ненужных для индекса» get-параметров (например, в 99% случаев использования WordPress), то перечислите их названия (без значений!) в любом порядке через & в одной строке:
clean-param: primer&plohoi-parametr2При этом то, в каких url и в каком порядке эти параметры встречаются, значения не имеет.
Каждый исключаемый get-параметр вставляется в clean-param один раз.
У clean-param есть одно классное свойство — она передаёт накопленную статистику поведенческих факторов результирующей («очищенной») странице. Этого не произойдёт, если вы воспользуетесь для закрытия таких страниц директивой Disallow. Однако, способ «через disallow» быстрее сработает. Вот, что платоны про это говорят:
Директива Clean-param позволяет передавать показатели со страниц с get-параметрами основным страницам, поэтому робот действительно еще может обращаться к страницам ограниченным такой директивой. Обращения постепенно прекращаются в течение нескольких недель после добавления директивы в файл robots.txt.
Если дожидаться прекращения обращений возможности нет, можно запретить индексирование таких страниц директивой Disallow. Тогда обращения к страницам прекратятся в течение суток после добавления запрета, однако какие-либо показатели в таком случае переданы не будут.
Платон Щукин. Поддежка Яндекса
После всех модификаций, не забудьте проверить получившийся robots.txt через Вебмастер
Директива host
Несмотря на то, что эта директива официально перестала использоваться Яндексом в 2018 году, а другие поисковики её и не использовали никогда, многие веб-мастера (и некоторые сервисы) по-прежнему вставляют её в свой robots.
Удалите строку с директивой host и забудьте про неё.
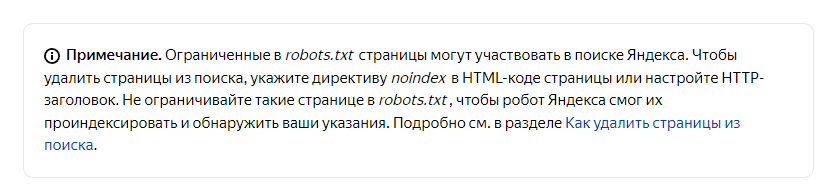
Изменение логики работы disallow
С весны 2023 года, Яндекс начал по-другому обрабатывать директивы robots. теперь, он работает, аналогично роботу Гугла — и страницы, помеченные, как disallow, могут быть проиндексированы
Если вы знаете какие-то другие трюки для robots.txt — напишите в камментах!
Над оптимизацией «под Яндекс» трудился Алексей.
Источники:
- справка и поддержка Яндекса;
- поддержка Tilda.
